- Můžete analyzovat HTML pomocí regexu?
- Jak získám obsah mezi značkami?
- Jak porovnáváte značky v HTML?
- Můžete analyzovat XML pomocí regulárního výrazu?
- Co je regex v HTML?
- Co je to vzor v HTML?
- Jak získáte text mezi značkami v Pythonu?
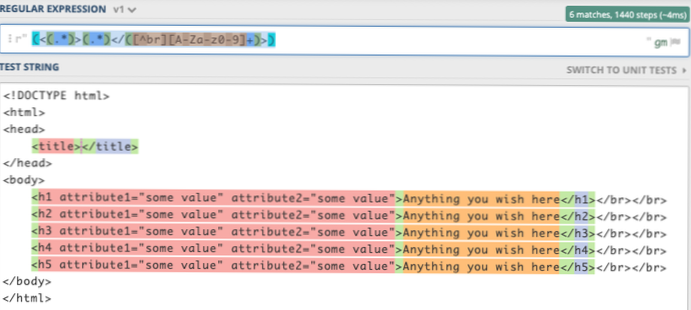
Můžete analyzovat HTML pomocí regexu?
Nelze analyzovat [X] HTML pomocí regulárního výrazu. Protože HTML nelze analyzovat pomocí regulárního výrazu. Regex není nástroj, který lze použít ke správné analýze HTML. ... HTML je jazyk dostatečně složitý, takže jej nelze analyzovat regulárními výrazy.
Jak získám obsah mezi značkami?
Funkce preg_match () je nejlepší volbou pro extrahování textu mezi tagy HTML pomocí REGEX v PHP. Chcete-li získat obsah mezi značkami, použijte v PHP regulární výrazy s funkcí preg_match (). Můžete také extrahovat obsah uvnitř prvku na základě názvu třídy nebo ID pomocí PHP.
Jak porovnáváte značky v HTML?
Platná značka HTML musí splňovat následující podmínky:
- Mělo by to začít úvodní značkou (<).
- Za ním by měl následovat řetězec dvojitých uvozovek nebo řetězec jednoduchých uvozovek.
- Neměl by umožňovat jeden řetězec uvozovek, jeden řetězec uvozovek nebo uzavírací značku (>) bez přiložených jednoduchých nebo dvojitých uvozovek.
Můžete analyzovat XML pomocí regexu?
Může analyzovat obvyklé značky bez jmenných prostorů, atributů a samozavíracích značek. Můžete ji dokonce krmit knihami. xml z příkladů MSXML SDK. (Ale bez řádku deklarace nahoře je deklarace XML jednou z mnoha věcí, které tento regulární výraz nemůže analyzovat.)
Co je regex v HTML?
Regulární výraz je objekt, který popisuje vzor znaků. Regulární výrazy se používají k provádění funkcí porovnávání vzorů a „hledání a nahrazení“ v textu.
Co je to vzor v HTML?
Atribut pattern určuje regulární výraz, který <vstup> při odeslání formuláře se zkontroluje hodnota prvku. Poznámka: Atribut pattern funguje s následujícími typy vstupu: text, datum, vyhledávání, url, tel, e-mail a heslo. Tip: Použijte atribut globálního názvu k popisu vzoru, který uživateli pomůže.
Jak získáte text mezi značkami v Pythonu?
Vzhledem k tagu String a HTML extrahujte všechny řetězce mezi zadanou značkou.
- Vstup : '<b>Gfg</ b> je <b>Nejlepší</ b>. miluji <b>Čtení CS</ b> z toho.', tag = “br”
- Výstup: ['Gfg', 'Best', 'Reading CS']
- Vysvětlení: Všechny řetězce mezi značkou „br“ jsou extrahovány.
![Vytváření kategorií, stránek a příspěvků na řídicím panelu [uzavřeno]](https://usbforwindows.com/storage/img/images_1/creating_categories_pages_and_post_on_dashboard_closed.png)