- Jak se zbavím chyby UTF-8?
- Co je chyba UTF8?
- Jak mohu změnit kódování na UTF-8?
- Jak se UTF8 ukládá?
- Jak mohu opravit problémy s Unicode?
- Jaké znaky nejsou povoleny v UTF-8?
- Co znamená UTF-8 v HTML?
- Proč UTF-8 nahradil ascii?
- Je UTF-8 stejný jako Ascii?
- Jaký je rozdíl mezi ANSI a UTF-8?
- Proč se používá UTF-8?
- Co znamená UTF-8?
Jak se zbavím chyby UTF-8?
2 odpovědi
- použijte znakovou sadu, která bude akceptovat jakýkoli bajt, jako je iso-8859-15 známý také jako latin9.
- pokud má být výstup utf-8, ale obsahuje chyby, použijte errors = ignore -> tiše odstraní znaky jiné než utf-8 nebo chyby = nahradit -> nahradí znaky jiné než utf-8 náhradní značkou (obvykle ? )
Co je chyba UTF8?
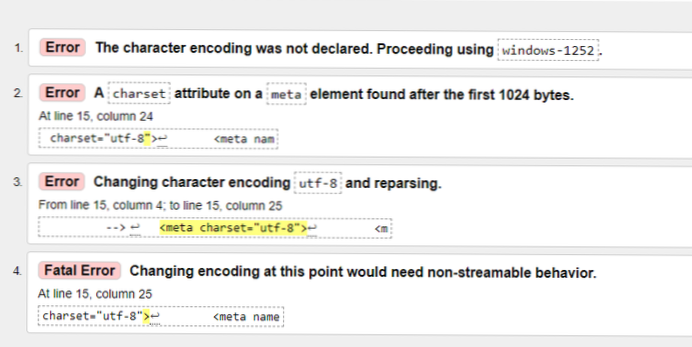
UTF-8 je dominantní formát kódování znaků v síti WWW. K této chybě dochází, protože software, který používáte, ukládá soubor v jiném typu kódování, například ISO-8859, místo UTF-8. Existují různá řešení, která můžete použít ke změně souboru na kódování UTF-8.
Jak mohu změnit kódování na UTF-8?
Klikněte na Nástroje a poté vyberte Možnosti webu. Přejděte na kartu Kódování. V rozevíracím seznamu Uložit tento dokument jako: vyberte Unicode (UTF-8). Klikněte na OK.
Jak se UTF8 ukládá?
Když software čte UTF-8 narazí na bajt počínaje 1, spočítá, kolik 1 následuje, než narazí na 0. ... Bajt ve tvaru 110xxxxx tedy říká, že prvních pět bitů znaku Unicode je uloženo na konci tohoto bajtu a zbytek bitů přichází v dalším bajtu.
Jak mohu opravit problémy s Unicode?
Prvním krokem k vyřešení vašeho problému s Unicode je přestat myslet na typ< 'str'> jako ukládání řetězců (tj. sekvencí znaků čitelných člověkem, a.k.A. text). Místo toho začněte myslet na typ< 'str'> jako kontejner pro bajty.
Jaké znaky nejsou povoleny v UTF-8?
Všimněte si, že značka pořadí bajtů (BOM) U + FEFF, alias prostor bez přerušení nulové šířky (ZWNBSP), se v UTF-8 nemůže objevit nekódovaný - bajty 0xFF a 0xFE nejsou v platném UTF-8 povoleny. Zakódovaný ZWNBSP se může v souboru UTF-8 objevit jako 0xEF 0xBB 0xBF, ale kusovník je v UTF-8 zcela zbytečný.
Co znamená UTF-8 v HTML?
charset = UTF-8 znamená Character Set = Unicode Transformation Format-8. Jedná se o oktetové (8bitové) bezztrátové kódování znaků Unicode. Ty by měly vrhnout více světla na porozumění ve Web Development and Scripting.
Proč UTF-8 nahradil ascii?
UTF-8 nahradil ASCII, protože obsahoval více znaků než ASCII, který je omezen na 128 znaků.
Je UTF-8 stejný jako Ascii?
U znaků představovaných 7bitovými kódy znaků ASCII je reprezentace UTF-8 přesně ekvivalentní ASCII, což umožňuje transparentní migraci zpět. Ostatní znaky Unicode jsou v UTF-8 zastoupeny sekvencemi až 6 bajtů, ačkoli většina západoevropských znaků vyžaduje pouze 2 bajty3.
Jaký je rozdíl mezi ANSI a UTF-8?
ANSI a UTF-8 jsou dvě schémata kódování znaků, která jsou široce používána v jednom nebo druhém okamžiku. Hlavní rozdíl mezi nimi je v použití, protože UTF-8 nahradil ANSI jako schéma kódování dle výběru. ... Protože ANSI používá pouze jeden bajt nebo 8 bitů, může představovat pouze maximálně 256 znaků.
Proč se používá UTF-8?
Proč používat UTF-8? Stránka HTML může být pouze v jednom kódování. Nelze kódovat různé části dokumentu do různých kódování. Kódování založené na Unicode, jako je UTF-8, může podporovat mnoho jazyků a může pojmout stránky a formuláře v jakékoli směsi těchto jazyků.
Co znamená UTF-8?
Základy UTF-8. UTF-8 (Unicode Transformation – 8-bit) je kódování definované Mezinárodní organizací pro standardizaci (ISO) v ISO 10646. Může představovat až 2097 152 kódových bodů (2 ^ 21), což je více než dost na pokrytí současných 1112 064 kódových bodů Unicode.